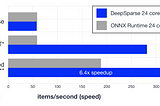
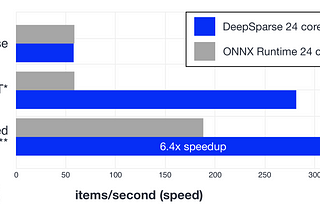
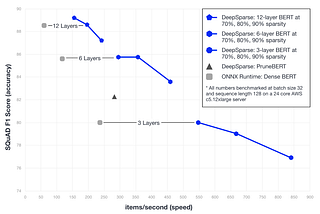
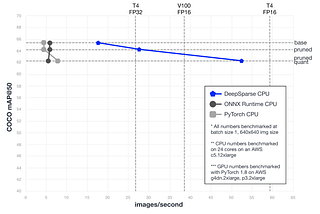
Published inDeep SparseoBERT: Compound Sparsification Delivers Smaller Accurate Models for NLPGPU-Level Latency on CPUs With 10x Smaller Models using oBERT + DeepSparseMay 20, 20221May 20, 20221
Published inDeep SparseSparsify Hugging Face BERT for Better CPU Performance & Smaller File SizeGet Started: Sparsify Hugging Face BERT Using Your DataOct 8, 2021Oct 8, 2021
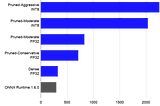
Published inDeep SparsePruning Hugging Face BERT: Using Compound Sparsification for Faster CPU Inference with Better…Pruning Hugging Face BERT: Apply both pruning and layer dropping sparsification methods to increase BERT performance anywhere from 3.3x to…Aug 23, 2021Aug 23, 2021
Published inCodeXYOLOv5: Tiny Footprint & GPU Results on CPUs — Neural MagicPrune and quantize YOLOv5 for a 10x increase in performance with 12x smaller model files.Aug 6, 2021Aug 6, 2021
Published inDeep SparseTutorial: Real-time YOLOv3 on a Laptop Using Sparse QuantizationSparsifying YOLOv3 (or any other model) involves removing redundant information from neural networks using algorithms such as pruning and…May 25, 2021May 25, 2021
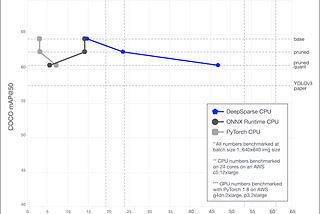
Published inDeep SparseYOLOv3 on CPUs: Sparsifying to Achieve GPU-Level PerformanceUse CPUs to decrease costs and increase deployment flexibility while still achieving GPU-class performance.Apr 1, 2021Apr 1, 2021
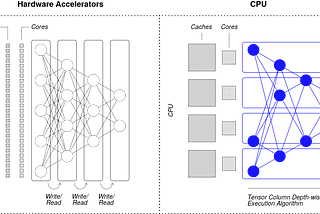
Published inDeep SparseDelivering GPU-Class Performance on CPUs: How Neural Magic’s Deep Sparse Technology WorksWhile mapping the neural connections in the brain at MIT, Neural Magic’s founders Nir Shavit and Alexander Matveev were frustrated with…Mar 22, 2021Mar 22, 2021
Published inDeep SparseSparsifying for Better ResNet-50 Performance on CPUsIn this post, we elaborate on how we measured, on commodity cloud hardware, the throughput and latency of five ResNet-50 v1 models…Mar 11, 2021Mar 11, 2021